
数据类型
教程地址:点击去往视频教程
go的数据类型分为以下几种:
- 数值类型:
整型和浮点型 - 布尔类型:
bool,值为true和flase - 字符类型:
byte和rune - 字符串类型:
string - 其他类型:
数组,指针,结构体,Channel,函数,切片,any,map
1. 整型
Go语言同时提供了有符号和无符号的整数类型。
- 有符号整型:int、int8、int16、int32、int64
- 无符号整型:uint、uint8、uint16、uint32、uint64、uintptr
注意:
8,32,64指的是位
有符号整型范围:
-2^(n-1) 到 2^(n-1)-1无符号整型范围:
0 到 2^n-1int和uint的范围不固定,可能是32位也可能是64位
无符号的整型
uintptr,是用于存放指针的,它没有指定具体的 bit 大小但是足以容纳指针。uintptr 类型只有在
底层编程时才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。
例子:
func main() {
//玩家血量
var health int64
//玩家等级
var level int16
fmt.Printf("玩家血量:%d, 玩家等级:%d \n", health, level)
}
2
3
4
5
6
7
2. 浮点型
Go语言支持两种浮点型数:
float32: 范围 约1.4e-45 到 约3.4e38float64:范围约4.9e-324 到 约1.8e308
floatStr1 := 3.2
//保留小数点位数
fmt.Printf("%.2f\n", floatStr1) //3.20
2
3
算术规范由 IEEE754 浮点数国际标准定义,该浮点数规范被所有现代的 CPU 支持
通常应该优先使用 float64 类型,因为 float32 类型的累计计算误差很容易扩散,并且 float32 能精确表示的正整数并不是很大。
var f float32 = 1 << 24;
fmt.Println(f == f+1) // true
2
浮点数在声明的时候可以只写整数部分或者小数部分
var e = .71828 // 0.71828
var f = 1. // 1
fmt.Printf("%.5f,%.1f",e,f)
2
3
很小或很大的数最好用科学计数法书写,通过 e 或 E 来指定指数部分
var avogadro = 6.02214129e23 // 阿伏伽德罗常数
var planck = 6.62606957e-34 // 普朗克常数
fmt.Printf("%f,%.35f",avogadro,planck)
2
3
3. 布尔型
布尔型数据只有true和false,且不能参与任何计算以及类型转换
func main() {
//玩家是否已经死亡
var isDead bool
fmt.Println(isDead)
}
2
3
4
5
4. 字符类型
Go语言的字符有以下两种:
- 一种是 uint8 类型,或者叫 byte 型,代表了 ASCII 码的一个字符。
- 另一种是 rune 类型,代表一个 Unicode 字符,当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型等价于 int32 类型。
byte 类型是 uint8 的别名,rune 类型是int32的别名
ASCII 码的一个字符占一个字节
ASCII 定义 128 个字符,由码位 0 – 127 标识。它涵盖英文字母,拉丁数字和其他一些字符。
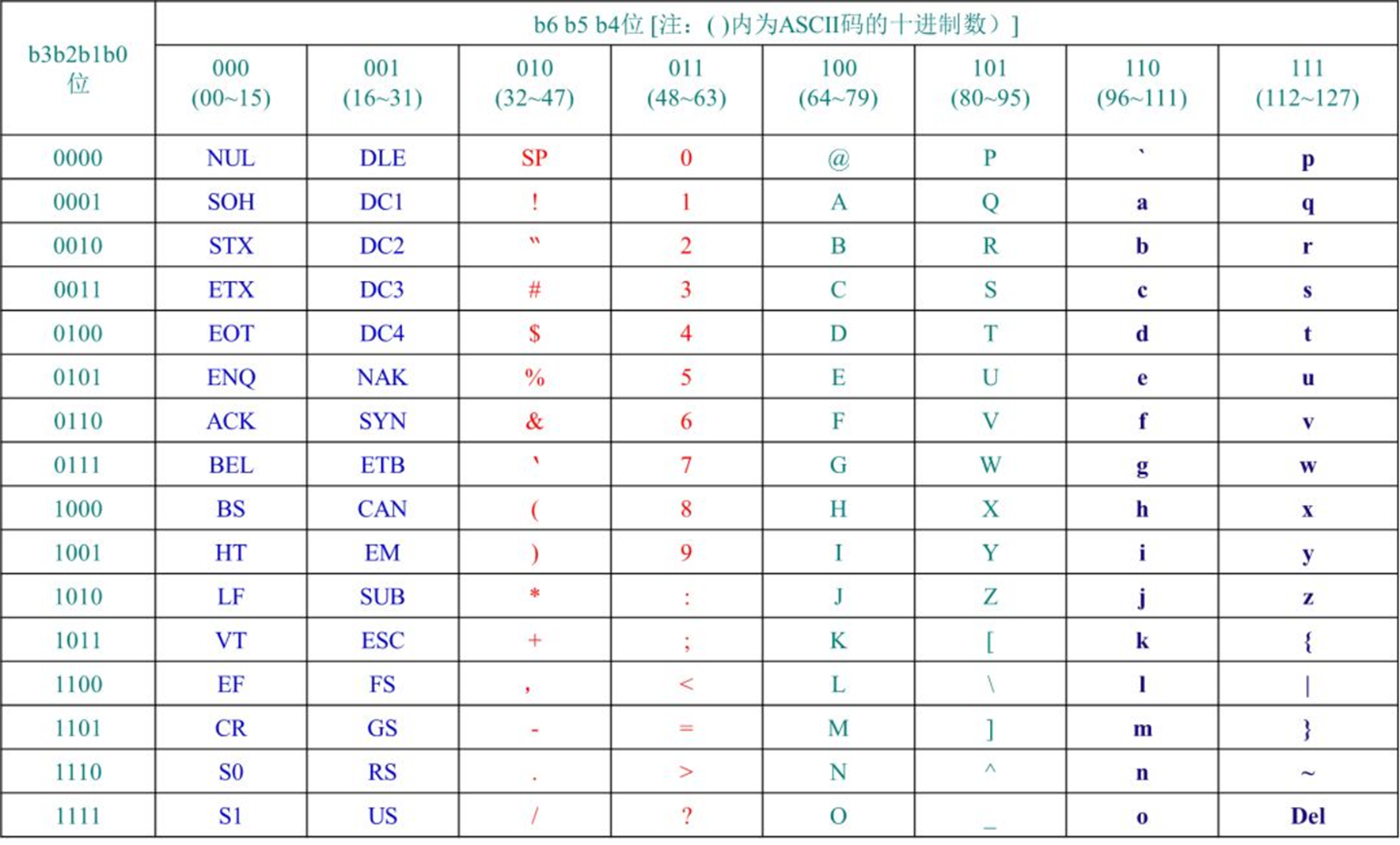
字符的定义:
//使用单引号 表示一个字符
var ch byte = 'A'
//在 ASCII 码表中,A 的值是 65,也可以这么定义
var ch byte = 65
//65使用十六进制表示是41,所以也可以这么定义 \x 总是紧跟着长度为 2 的 16 进制数
var ch byte = '\x41'
//65的八进制表示是101,所以使用八进制定义 \后面紧跟着长度为 3 的八进制数
var ch byte = '\101'
fmt.Printf("%c",ch) //A
2
3
4
5
6
7
8
9
Unicode 是 ASCII 的超集,数字0–127在ASCII中的含义与在Unicode中的含义相同。
Unicode为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
在书写 Unicode 字符时,需要在 16 进制数之前加上前缀\u或者\U。
如果需要使用到 4 字节,则使用\u前缀,如果需要使用到 8 个字节,则使用\U前缀。
func main() {
var ni rune = 20320 //你
var hao rune = '\u597D' //好
var hao1 = rune('好')
//格式化说明符%c用于表示字符,%v或%d会输出用于表示该字符的整数,%U输出格式为 U+hhhh 的字符串。
fmt.Printf("%c,%c,%U", ni, hao, hao1) //你,好,U+597D
}
2
3
4
5
6
7
Unicode 包中内置了一些用于测试字符的函数,这些函数的返回值都是一个布尔值,如下所示(其中 ch 代表字符):
- 判断是否为字母:unicode.IsLetter(ch)
- 判断是否为数字:unicode.IsDigit(ch)
- 判断是否为空白符号:unicode.IsSpace(ch)
4.1 UTF-8 和 Unicode 有何区别?
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题:
- 第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是
0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
UTF-8 就是使用最广的一种 Unicode 的实现方式,是一种统一的编码方式。
类似的还有UTF-16(字符用两个字节或四个字节表示),UTF-32(字符用四个字节表示)。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx1
2
3
4
5
6
7
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;
如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF);
因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。
然后从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。
这样就得到了严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
5. 字符串型
一个字符串是一个不可改变的字节序列,字符串可以包含任意的数据,但是通常是用来包含可读的文本,字符串是 UTF-8 字符的一个序列。
字符串的定义:var mystr string = "hello"
go语言从底层就支持UTF-8编码。
在Go语言中字符串也可以根据需要占用 1 至 4 个字节,这与其它编程语言不同。
Go语言这样做不仅减少了内存和硬盘空间占用,同时也不用像其它语言那样需要对使用 UTF-8 字符集的文本进行编码和解码。
字符串中可以使用转义字符来实现换行、缩进等效果,常用的转义字符包括:
\n:换行符\r:回车符\t:tab 键\u 或 \U:Unicode 字符\\:反斜杠自身
func main() {
var str string = "码神之路的go教程\nGo大法好"
//码神之路的go教程
//Go大法好
fmt.Print(str)
}
2
3
4
5
6
如果使用``反引号,会被原样进行赋值和输出
fmt.Println(`\t ms的go教程Go大法好`) // \t ms的go教程Go大法好
fmt.Println(`\t ms的go教程
Go大法好`) //使用反引号 可以进行字符串换行
//反引号一般用在 需要将内容进行原样输出的时候 使用
2
3
4
string是不可变,也就是初始化后不能再修改其值,除非重新赋值
func main() {
str := "mszlu"
//str[0] = "d" //不行
str = "hello mszlu" //ok
fmt.Println(str)
}
2
3
4
5
6
思考:hello,码神之路的go教程 占用几个字节?
package main
import (
"fmt"
)
func main() {
//中文三字节,字母一个字节
var str string = "hello,码神之路的go教程"
fmt.Printf("mystr01: %d\n", len(str))
}
2
3
4
5
6
7
8
9
10
11
6. 类型转换
func main() {
var a int = 10
var b float64 = 3.14
//不能类型之间不能进行运算
//fmt.Println("a+b=", a+b) //错误
fmt.Println("a+b=", float64(a)+b) //正确
}
2
3
4
5
6
7
由于Go语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明:
//类型B的值 = 类型B(类型A的值)
valueOfTypeB = typeB(valueOfTypeA)
2
示例:
a := 5.0
b := int(a)
2
类型转换只能在定义正确的情况下转换成功,例如从一个取值范围较小的类型转换到一个取值范围较大的类型(将 int16 转换为 int32)。
当从一个取值范围较大的类型转换到取值范围较小的类型时(将 int32 转换为 int16 或将 float32 转换为 int),会发生精度丢失的情况。
只有相同底层类型的变量之间可以进行相互转换(如将 int16 类型转换成 int32 类型),不同底层类型的变量相互转换时会引发编译错误(如将 bool 类型转换为 int 类型):
func main() {
var a bool = true
fmt.Println("a convert int", int(a)) //错误
}
2
3
4
6.1 修改字符串
字符数组实际上就是字符串,所以
[]byte和[]rune可以和string互相转换
Golang语言的字符串是不可变的
修改字符串时,可以将字符串转换为[]byte进行修改
[]byte和string可以通过强制类型转换
案例:将8080改为8081
package main
import "fmt"
func main() {
s1 := "localhost:8080"
fmt.Println(s1)
// 强制类型转换 string to byte
strByte := []byte(s1)
// 下标修改
strByte[len(s1)-1] = '1'
fmt.Println(strByte)
// 强制类型转换 []byte to string
s2 := string(strByte)
fmt.Println(s2)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20